Databáze v systému OSLO
Následující text je volným překladem, učebnicového textu Database Tutorial , který je součástí Oslo Help Overview. Původní příkazy tlex_x byly počeštěny na cocka_x stejně jako databáze simlens_x na cocka_x. Některé příklady byly detailněji rozebrány a doplněny o další.
1. Vytvoření jednoduché databáze
Výraz databáze popisuje souhrn strukturovaných údajů. S termínem databáze jste se jistě setkali v souvislosti s osobními nebo obchodními daty, jako jsou jména, adresy, telefonická čísla atp. Nicméně na tomto místě máme zájem hlavně o technické údaje jakými jsou např. rozměry a údaje o materiálu, které popisují čočkový systém. V podstatě potřebujeme jen tři typy dat: celá čísla, reálná čísla (důsledně používáme desetinnou tečku), a stringové proměnné (znaky, slova, atp.). S dalšími typy dat, jako jsou měna nebo datum si nebudeme dělat starosti. Na druhé straně některé aspekty dat, jako je například přesnost reálných čísel jsou mnohem důležitější než u řady jiných obecných databázových aplikací.
CCL databáze nekonkuruje obecným databázovým aplikacím, ani optickému databázovému software pro optiku. Poskytuje jen uživatelům snadno dostupný interface pro tabulkový procesor, který umožňuje spravovat technické údaje. Jestliže si jednou sestavíte CCL databázi, můžete ji vizuálně analyzovat a manipulovat s ní. V porovnání s obecným databázovým softwarem je CCL databáze velmi rychlá. Její rychlost vynikne zejména když provádíte detailní technickou analýzu spojenou s optickými výpočty. Na druhé straně jste ale omezeni jen na relativně malou databázi, která má méně než 2000 záznamů a 300 polí. Důraz je položen více na rychlost a snadný přístup, než na mocné vyhledávací schopnosti.
V dále uvedených učebních příkladech se naučíte vytvořit CCL databázi, která obsahuje několik tenkých čoček, které můžete třídit podle různých specifikací. Můžete ji použít, buď jako standardní nástroj, nebo v kombinaci s OSLO a jinými programy (Word, Excel, 1-2-3, atd.), které každodenně používáte. K jasnému pochopení příkladů, budeme postupovat po jednoduchých krocích. V prvním kroku se naučíme: vytvořit počáteční databázi, manipulovat s daty, přecházet od CCL databáze k obecným tabulkovým procesorům a zpět. Dále se naučíte používat některé analytické nástroje, které umožní provádět jednoduché výpočty. Nakonec využijete funkci zpětného volání, která umožňuje automatický výpočet.
Po zvládnutí uvedených příkladů budete moci vytvářet skutečné programy s okny. Neobávejte se, nemusíte být počítačový experti, abyste to mohli dělat. Hlavní smysl CCL databáze je vytvořit dostupný programovací nástroj k vytváření oken, který bude k dispozici výzkumníkům a inženýrům a ušetří jim hodně času k jiným věcem. Jestliže již znáte uživatelský interface OSLO, pak můžete projít tuto lekci s příklady za dvě hodiny. Jestliže ne, pak to bude o trochu déle, ale získáte přitom cenné znalosti.
Definice, vytváření a užívání CCL databáze
Nejprve musíte rozhodnout, která data má vaše databáze zahrnovat. Ve většině databází musíte také uvážit vztahy mezi daty, ale to není nyní náš případ. Vazby v CCL databázi jsou omezeny na ty, které mohou být popsány v dvourozměrném poli (tabulce). V tomto uspořádání se řádky pole často označují jako záznamy a sloupce jako pole. Z jiného pohledu jsou řádky objekty a sloupce jejich vlastnosti. V technické praxi se sloupce někdy uvažují jako mnohodimenzionální vektory.
V našich příkladech budeme sledovat data, která se vztahují k jednoduchým čočkám: přední poloměr křivosti, zadní poloměr křivosti, tloušťku, materiál a průměr čočky. Ostatní důležité údaje jako je například kvalita povrchu, tenké vrstvy, fazety atp. nejsou uvažovány.
Předchozí informace zahrnuje téměř všechno co potřebujete k vytvoření CCL databáze. Je zde však ještě jedna důležitá položka, kterou je jméno pole, které bude data obsahovat. Pole je místo, kde jsou parametry uloženy. CCL databáze je paměťově orientována, což znamená, že když užíváte data (například je vkládáte nebo třídíte), pak pracujete s přechodnými daty, která existují pouze v paměti počítače. Jestliže počítač vypnete, vaše data budou ztracena, jestliže je před tím neuložíte na disk. Jestliže jsou data v paměti počítače, pak říkáme, že databáze je otevřená. Jestliže je databáze uzavřená, pak data existují pouze na disku.
CCL databázové pole jsou mírně modifikovaná pole standardních databází, která se označují jako ohraničená datová pole. Ohraničené datové pole je nějaké textové pole, ve kterém každý záznam odpovídá řádku. Speciální znak, který není obsažen v zaznamenávaných datech odděluje pole každého záznamu. Jestliže je tímto speciálním znakem čárka, pak se pole označuje jako CSV pole (comma-separated-value). Užívají se i jiné oddělovače jako například tabelátor, nebo vlnovka. V CCL je implicitní oddělovač tabelátor. Prakticky jakýkoliv databázový software (včetně CCL) je schopen číst ohraničená datová pole. Jedna z cest jak vytvořit novou CCL databázi je vyjít z nějakého CSV pole. To uděláme i v našem případě.
V OSLO jsou databázová pole umístěna ve složkách CDB. První složka CDB je umístěna ve vaší osobní složce Private a druhá CDB složka je umístěna ve veřejném adresáři Public. Když otevíráte nějaké databázové pole bude program standardně hledat nejprve ve vašem adresáři Private CDB. Při ukládání nějakého pole do této složky se název ukládaného pole pole automaticky doplní o přívěsek .cdb . Jak již bylo zmíněno, pole jsou ohraničena určitou speciální informaci, která předchází aktuální data. Na tuto speciální informaci se podíváme později. Abychom neztratili tuto informaci, tak CCL databázi vždy zapisujeme jako *.cdb pole. To může být ale nicméně čteno, stejně jako obecné CSV a jiná ohraničená pole, která se před zápisem automaticky přemění na *.cdb pole. Jednoduchý program může přeměnit *.cdb pole na CSV pole, nebo jiná ohraničená datová pole, ale protože speciální data v CDB poli jsou sama ohraničeným textovým datem, je možno importovat CDB pole do jiného software a vypustit tyto speciální řádky.
Dosud jsme se naučili:
CCL databáze je paměťový systém navržený pro vkládání dat, úpravu dat, a provádění jednoduchých manipulací s daty (seřazování, přeskupování, atp.). Data mohou být čísla typu integer, real a string. CCL databáze není konkurent obecně používaných databází.
Ke vstupu a manipulaci s daty se používá tabulkový procesor (spreadsheet).
CCL databáze je uložena v ohraničeném datovém poli, které obsahuje pouze textové informace (tj. není binární). Tato pole jsou kompatibilní s jiným softwarem, ale také zahrnuje určité hlavičkové řádky, které popisují datovou strukturu. Data jsou obvykle uložena v CDB složce a užívají přívěsek *.cdb .
Nyní jsme připraveni sestavit jednoduchou databázi čoček. Existují dva způsoby jak to provést. První způsob je vytvoření nové prázdné databáze a pak přidávání řádky a sloupce podle potřeby.
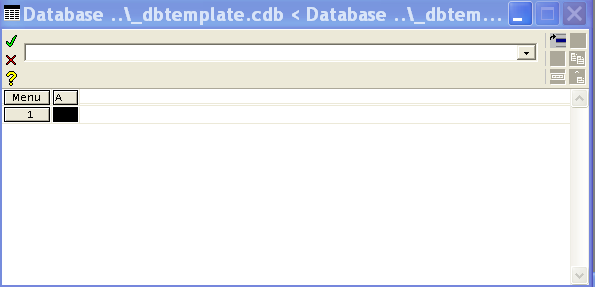
Abyste to mohli udělat, začněte spuštěním příkazu Open Database, který naleznete v hlavním menu. Zobrazí se vám nabídka se jmény cdb databází, které jsou uloženy ve vašem privátním CDB adresáři. Mezi nimi je uvedena i databáze „_dbtemplate.cdb“ , což je speciální jméno databáze, které vytváří a otevírá prázdnou databázi. Po odklepnutí se zobrazí okno s prázdnou databází „_dbtemplate.cdb“:
Jméno databáze „_dbtemplate.cdb“ nemůžete použít k uložení nějaké konkrétní databáze. Chcete-li databázi uložit, musíte jí nejprve vytvořit jiné jméno. To uděláte pomocí příkazů v Menu>>SaveAs v databázovém tabulkovém procesoru (spreadsheetu). Ujistěte se, že jste omylem nepoužili příkaz File>>SaveAs z hlavního menu, který je určen k ukládání dat optických systémů, ale ne k ukládání databází .cdb.
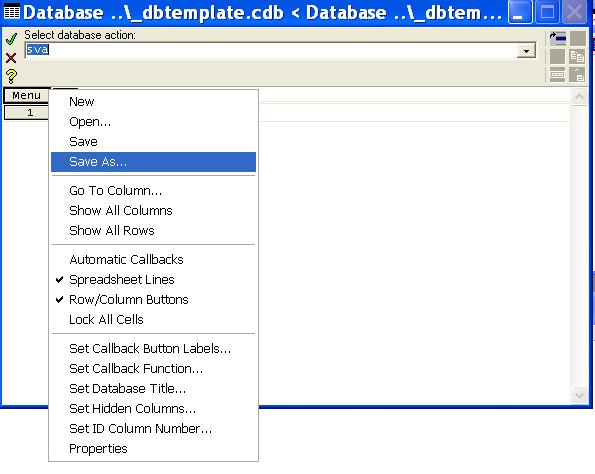
Po kliknutí na „Save As ...“ dostanete nabídku, kam zapíšete a následně uložíte nové jméno pro databázi. V našem příkladě se rozhodneme pro název databáze „jedcocky.cdb“ protože následně vytvoříme databázi jednoduchých čoček.
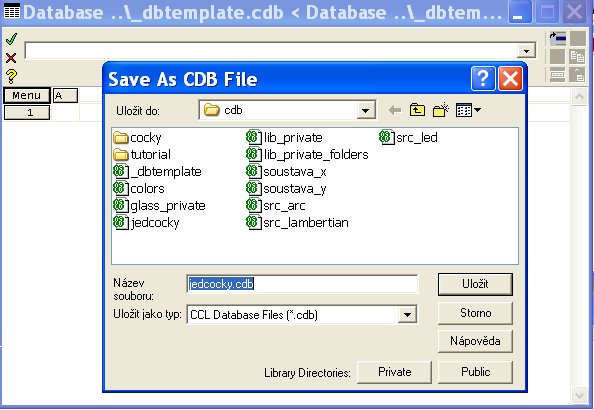
Nově vytvořená databáze „jedcocky.cdb“ má již své nové jméno, ale je stále prázdná. Jinak řečeno je to databáze, která má jeden sloupec „A“ a jeden řádek „1“ , ve ktrém ale není zapsaná žádná hodnota. K tomu abychom mohli databázi naplňovat musíme vytvořit nové sloupce, které budou obsahovat data určitých entit. Chceme-li zaznamenat například jen základní konstrukční parametry jednoduchých čoček, které máme v nějakém šuplíku, budou to například údaje:
poloměr křivosti 1. plochy, tloušťka čočky, poloměr křivosti 2. plochy, průměr čočky, jméno skla ze kterého je čočka zhotovena, počet čoček, název čočky.
Pro jednoduchost každému sloupci přiřadíme jednoslovný výstižný název bez interpunkci, např.: polomer1, tloustka, polomer2, prumer, sklo, počet, název.
Každý sloupeček bude obsahovat data určitého typu: reálná čísla, textový údaj nebo celá čísla. Tyto tři typy jsou jediné typy, které databáze CDB připouští. Každý typ může mít ovšem různou přesnost. Proto si také musíme nejprve rozmyslet jakou maximalní délku zobrazení připustíme a v případě typu real také uvedeme na kolik desetinných míst se má příslušná hodnota zobrazovat.
Nyní můžeme začít databázi tvořit. Klikneme na názvu jediného sloupce, který máme v databázi k dispozici „A“ a dostaneme nabídku:
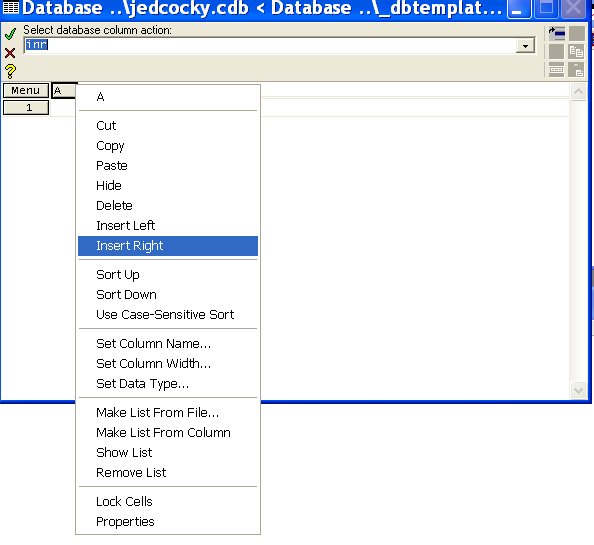
Nejprve přejmenujeme první sloupec z názvu „A“ na název „polomer1“ . K tomu použijeme nabídku „Set Column Name“. Dostaneme výzvu k zápisu jména sloupce databáze „Enter db colname“ a jméno zapíšeme:
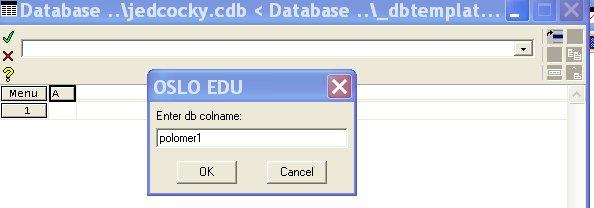
Po odkliknutí „OK“ se název „polomer1“ zapíše do databáze v RAM paměti počítače, nicméně v tabulkovém procesoru se zobrazí jen „pol“, protože šířka sloupce není dostatečná. Proto znovu klikneme na názvu sloupce „pol“ a z nabídky vybereme „Set Column Width...“. Následně na výzvu „Enter db width“ zapíšeme číslo 8. Pak se název sloupce již zobrazí celý. Dalším krokem je nastavení datového typu údajů v sloupci. To provedete dalším kliknutím na názvu sloupce a vybráním „Set Data Type...“
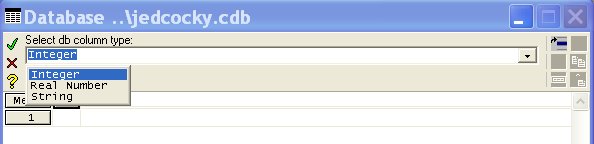
Protože
do tohoto sloupce vkládáme poloměry křivosti což jsou
reálná čísla, vybereme typ „Real Number“.
Po výběru se v 1. řádku sloupce „polomer1“ objeví reálné číslo 0.0e+000. Klepneme-li na místě tohoto čísla můžeme hodnotu přepsat například na číslo 50. Novým kliknutím na „Set Column Width...“ můžeme vybrat v případě „Real Number“ přesnost na kolik desetinných míst se mají proměnné zobrazovat.
Další sloupec vpravo od sloupce „polomer1“ vytvoříme tak, že na názvu „plomer1“ klikneme a vybereme „Insert Right“. Název sloupce, šířku sloupce a typ vkládaných čísel vytvoříme obdobně jako v případě 1. sloupce. To uděláme i pro další sloupce, takže nakonec dostaneme:
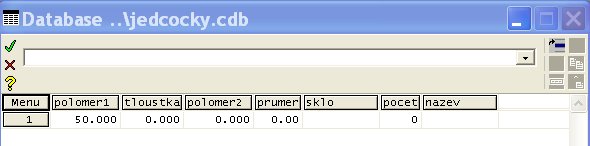
Máme-li
takto připravenou kostru databáze, můžeme ji začít
naplňovat údaji. K tomu slouží dva způsoby.
1. 1. Přímé ruční vkládání hodnot do tabulkového procesoru
Do prvního řádku můžeme nyní zapsat hodnoty příslušné první čočce. Po zapsání čísla zmáčkneme TAB a kurzor přeskočí do vedlejšího sloupce. Současné zmáčknutí SHIFT+TAB vede k přeskoku kurzoru do předchozího sloupce. Po zmáčknutí ENTER kurzor opustí tabulku. Údaje pro další čočky zapisujeme do dalších řádků, které vytvoříme obvyklým způsobem, to je kliknutím na prvním čísle řádku pravým knoflíkem myši a vybráním v nabídnutém menu řádky „Insert Before“ nebo „Insert After“.
Tak můžeme vytvořit například jednoduchou databázi 5 čoček:
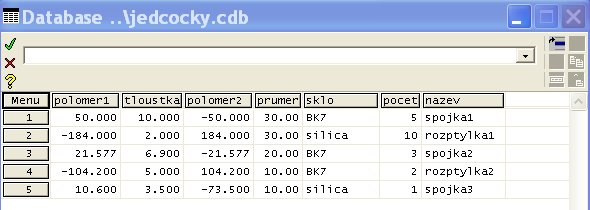
1. 2. Vložení hodnot do databáze kopírováním z nějaké CSV tabulky
Jiná snadnější cesta jak vytvořit nějakou databázi je prostřednictvím nějakého editoru. Uvažujme, že chceme konstrukční parametry určitého optického systému vytvořit jako databázové pole. Např. tmelený dublet zahrnuje 3 poloměry křivosti, 2 tloušťky, 3 průměry optických ploch a tři indexy lomu (dvě čočky a obrazový prostor, index lomu předmětového prostoru do databáze nezahrneme). Do Editoru v systému Oslo pak zapíšeme jednotlivé hodnoty oddělené čárkami tak, jak je patrné v dolním obrázku. Pak soubor zapíšeme např. pod názvem soustava_CSV.cdb a uložíme do databáze CDB. Poté co otevřeme Open Database..., dostaneme obraz tabulky CCL databáze tak, jak jsme na něj již zvyklí z předchozího výkladu.
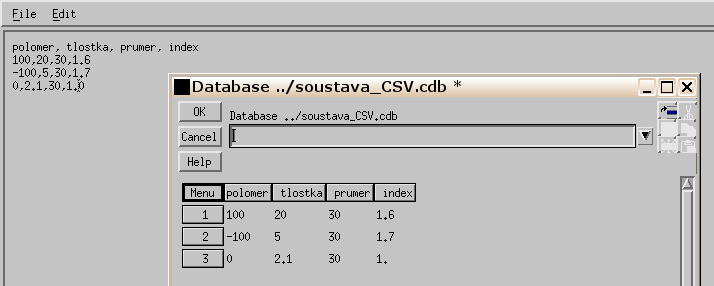
Všechna data jsou v takto vytvořené databázi zachycena jako stringové hodnoty. Proto je většinou nutno obvyklým způsobem tabulku editovat a typ dat a požadovanou přesnost zobrazení upravit. případně upravit. Poté co to provedete uložte databázi soustava_CSV.cdb obvyklým způsobem.
Otevřete-li nyní databázi v textovém editoru, uvidíte změnu, která pozůstává v přidání dvou řádků před původní CSV soubor:
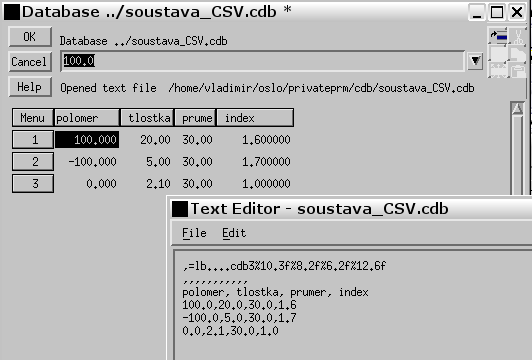
Přidané řádky popisují strukturu pole. V prvním řádku vidíte strukturu připomínající formát výstupu používaný v jazyku C.
Někdy je vhodné mít v databází sloupec, který obsahuje nejen hodnotu určité veličiny, ale raději název této veličiny s odkazem na její hodnotu. Potřebujeme tedy nějak vytvořit seznam (číselník), který určitému názvu přiřadí hodnotu. Pak bude stačit zapisovat názvy a databáze dokáže tomuto názvu přiřadit ze seznamu příslušnou hodnotu. Například zapíšeme do databáze seznam s názvy optických skel, kterým přiřadíme hodnoty indexu lomu pro určitou vlnovou délku. Buňky, které obsahují takový seznam musí být typu string a musí obsahovat znaménko rovnosti =. Zápis má tvar: jméno=hodnota.
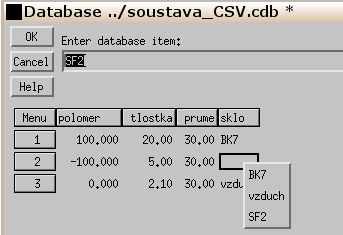
Na příkladě názvu skla a indexu lomu ukážeme postup, jak je možno takový seznam vytvořit a využívat. Nejprve upravíme předchozí databázi soustava_CSV.cdb tak, že změníme sloupec index z typu "Real Number" na "String" . Název sloupce "index" změníme na "sklo" a obsah buněk sloupce změníme z hodnot indexu lomu na názvy skel (např. BK7, SF2, vzduch). Vlevo vedle sloupce "sklo" vytvoříme nový sloupec "sklo" typu string a délky 22. V tomto novém sloupci nejprve vytvoříme zmíněný seznam a to tak, že do jednotlivých řádků nového sloupce "sklo" postupně zapisujeme BK=1. 5168, SF2=1.64769 , vzduch=1.0000. Počet zápisů v seznamu může být různý od počtu řádků využívaných ke zobrazení konstrukčních parametrů konkrétního optického systému. Po dopsání všech údajů vybereme z nabídkového menu u nového sloupce "sklo" příkaz pro vytvoření seznamu "Make list from column". V novém sloupci "sklo" se zobrazí již jen názvy skel. Hodnotu šířky sloupce "sklo" nyní změníme na hodnotu 6. Výsledná tabulka vypadá následovně:
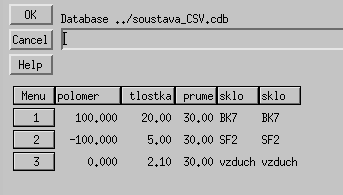
Čtvrtý sloupec "sklo" z databáze odstraníme. Kdykoliv nyní najedeme myší na určitou buňku zbylého sloupce "sklo" a klikneme levým tlačítkem, zobrazí se padací menu, ve kterém můžeme vybrat jednu z položek seznamu:
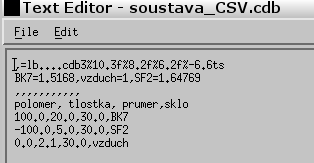
Po uložení této databáze se můžeme v textovém editoru podívat jak se změnil zdrojový kód v CSV. V druhém řádku tabulky je uveden zapsaný seznam:
Znalost struktury zdrojového zápisu CCL databáze umožňuje následně do ní prostřednictvím textového editoru jednoduše dopisovat další položky seznamu, nebo i měnit podstatnější vlastnosti CCL databáze.
Mimo uvedený způsob vytvoření seznamu existuje ještě jiná možnost pomocí převzetí hodnot z jiného pole, která se realizuje pomocí příkazu "Make list from file", který také najdeme v nabídkovém menu sloupce. Tato metoda využívá předem vytvořený seznam, který je uložen v nějakém poli *.cdb , který je v podadresáři Lists adresáře CDB.
Ačkoliv část dat není v otevřeném tabulkovém procesoru databáze zobrazena (hodnoty inexu lomu), je dostupná příkazům, které využívají tabulový procesor prostřednictvím zpětného volání, jak je popsáno v následující kapitole. Zpětné volání je významný a silný nástroj CCL databáze a poskytuje potřebnou komunikaci mezi databází a CCL programem. Umožňuje CCL programu používat data z databáze. Pro názornost uveďme příklad příkazu dbgse (plný název je db_get_string_element).
Napíšeme-li do příkazového řádku příkazy:
dbgse(str1,1,4); prt str1 - zobrazí se hodnota elementu přiřazená v řádku 1 a sloupci 4 sklu BK7, což je hodnota jeho indexu lomu 1.5168.
Možnosti, které Menu databázového CCL procesoru nabízí umožňují řešit široký okruh aplikací.
V Menu nalezneme například odkaz "Set Database Title" což umožňuje databázi pojmenovat. Jestliže pomocí "Set Database Title" zavedeme např. jméno Dublet 1dostaneme pak zobrazení:
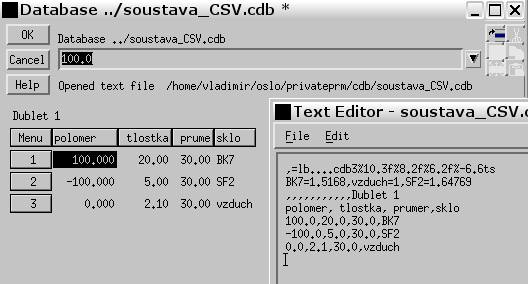
V detailnějším výpisu obsahu databáze v textovém editoru vidíme kde je název "Dublet 1" umístěn.
2. Provázání programu a databáze
V této kapitole ukážeme možnosti provázání zapsaného příkazu v CCL programu s CCl databází. Takové provázání umožňuje programu snadný přístup k datům prostřednictvím CCL databáze. V následujících šesti příkladech CCL příkazů ukážeme jak lze postupovat. Přitom se seznámíte s řadou funkcí, které práci s databázemi umožňují. Všech 6 příkazů je zapsáno v jediném programu, který jsme nazvali cocky.ccl, a který naleznete na našich stránkách.
2. 1. Program nezávislý na databázi
V řadě případů není pro funkci programu CCL vazba na nějakou databázi významná. Chceme-li například napsat program pro výpočet ohniskové vzdálenosti tenké čočky, která je definována poloměry, tloušťkou a indexem lomu můžeme sestavit jednoduchý příkaz, který nazveme cocka_1:

2. 2. Funkce přebírá data z otevřené databáze bez zpětné vazby
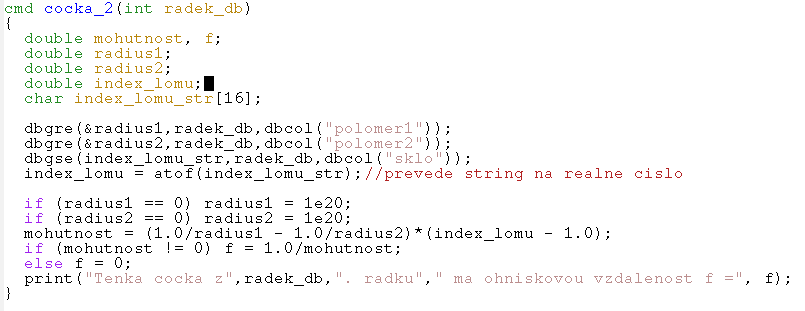
Uvažujme, že máme databázi konstrukčních parametrů jednoduchých čoček a chceme určit jejich ohniskové vzdálenosti a optické mohutnosti. Nechť naše databáze je koncipována stejně jako ta, kterou jsme uvedli na konci kapitoly 1. 1. Využití příkazu cocka_1 z předchozí kapitoly je ke zjištění ohniskových vzdáleností čoček v databázi sice možné, ale poněkud nepohodlné. Proto je vhodnější vytvořit nový příkaz cocka_2, který dokáže sám vybrat požadované konstrukční parametry z databáze, kterou si označíme jako jedcocka_2.cdb .
Příkaz cocka_2 se spustí z příkazové řádky a je schopen z otevřené databáze jedcocka_2.cdb vybrat data a výsledek zobrazit v textovém okně. Přitom neexistuje žádná zpětná vazba mezi databází a příkazem.
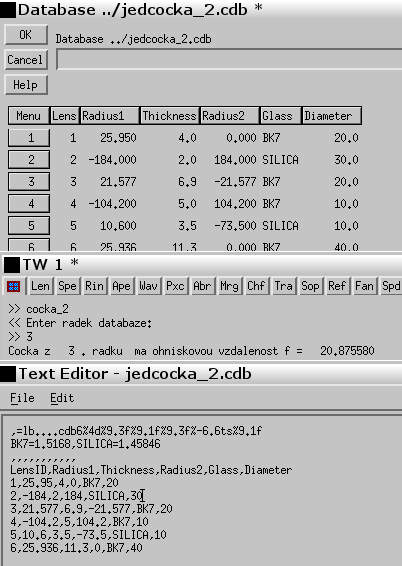
Aby se mohl příkaz cocka_2 použít, musí být otevřena databáze jedcocka2_cdb. Do příkazového řádku v CCL databázi zapíšeme příkaz cocka_2 a zmáčkneme Enter. Následně jsme vyzváni, abychom do příkazového řádku CCL databáze zapsali číslo řádku, ve kterém jsou uložena konstrukční data čočky, o kterou máme zájem. Po zapsání zmáčkneme Enter a v textovém okně se zobrazí výsledek. Příkaz cocka_2 využívá následující funkce, které zpřístupňují data z databáze:
dbcol("polomer1") - vrací číslo sloupce, jehož název v hlavičce CCL databáze je "polomer1"
dbgre(&radius1, radek_db, sloupec_db) - obsah buňky typu real, která je na řádku radek_db a v sloupci sloupec_db se uloží do proměnné radius1. Operátor adresy & před radius1 zde musí být, protože se jedná o skalár nikoliv o pole, což vyplyne i z následujících příkazů. Plný název příkazu je db_get_real_element.
dbgse(index_lomu_str, radek_db, sloupec_db) - obsah buňky typu string, který je na řádku radek_db a v sloupci sloupec_db se uloží do stringové proměnné index_lomu_str. Plný název příkazu je db_get_string_elemen.
Zdrojový kód příkazu cocka_2 je následující:
2. 3. Databáze volá funkci a ta z ní přebírá data - zpětná vazba
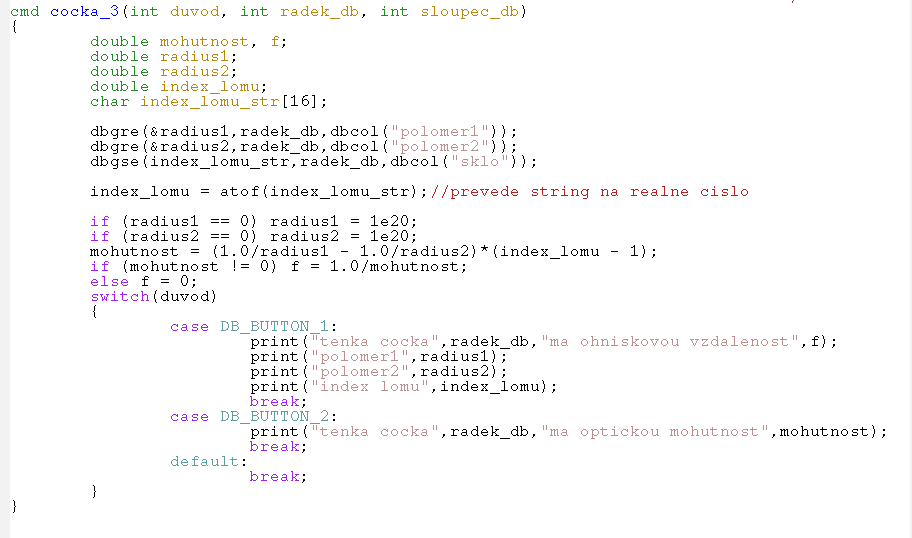
Zpětná vazba umožní uživateli zjednodušit práci. Do CCL databáze lze přidat ovládací knoflíky, které budou volat funkci zpětného voláni cocka_3. Funkce cocka_3 je vyvolána zmáčknutím jednoho z ovládacích knoflíků databáze jedcocka_3.cdb. To je zajištěno tím, že databáze odkazuje na funkci cocka_3. Vyberete-li v databázi nějaký element a následně kliknete na některém z ovládacích knoflíků (Ohnisková vzdálenost, Optická mohutnost) objeví se výsledek v textovém okně. V databázi však není nastavena kontrola Automatic callbasks.
Všechny funkce zpětného volání mají 3 argumenty - důvod, řádek databáze a sloupec databáze. radek_db a sloupec_db označuje řádek a sloupec ze kterého je zpětné volání provedeno. Argument duvod označuje důvod, je typu ineger a je definován v hlavičkovém souboru public/ccl/inc/db_defines.h, na který je odkaz hned na začátku programu v řádku #include . Argument duvod říká funkci zpětného volání, proč byla volána. V tomto případě je důvodem kliknutí na některý knoflík. Podle toho zda to byl DB_BUTTON_1, nebo DB_BUTTON_2 závisí zda se zobrazí ohnisková vzdálenost nebo optická mohutnost.
Dále je uveden zdrojový kód příkazu cocka_3:
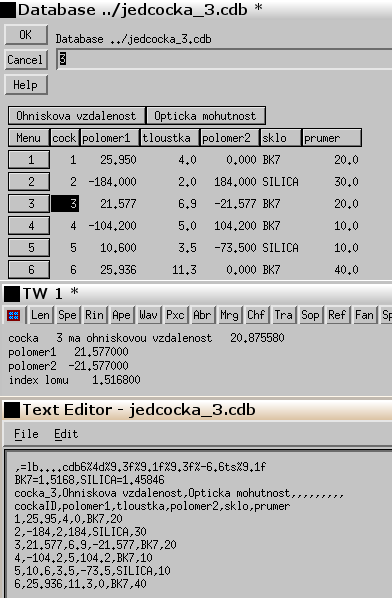
Vzhled databáze, výsledek výpisu v textovém okně po kliknutí na řídícím knoflíku "Ohnisková vzdálenost" a detailní obsah databáze jedcocka_3.cdb v textovém okně je patrý z následujícího screenshotu:
2. 4. Databáze volá funkci automaticky při každé změně a ta o tom dává zprávu
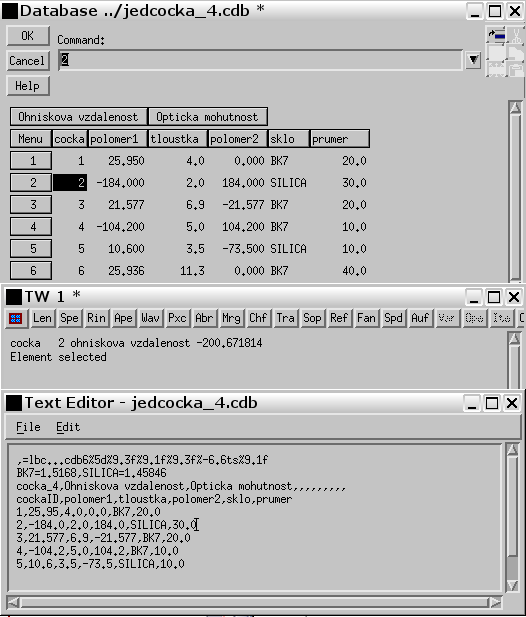
V tomto příkladě použitá databáze jedcocka_4.cdb se od předchozího odlišuje jen tím, že je zapnut Automatic callbasks a odkazuje na příkaz cocka_4, který s tímto zapnutím uvažuje. To zajišťuje, že zpětná vazba je generována automaticky programem souběžně s kliknutím na ovládacích knoflících. V uvedeném příkladě mohou byt generovány různé typy zpětných vazeb pomoci tabulového procesoru CCL,
a výstupy jsou zobrazovány v textovém okně. Příkaz cocka_4 bude volán i když je tabulkový procesor otevírán nebo zavírán. V tom okamžiku je číslo řádku databáze (radek_db) rovno nule. Protože první aktuální řádek v tabulkovém procesoru je 1, musí být příchozí příkaz chráněn instrukci, kterou můžeme napsat např. ve tvaru "if (dbrow > 0) ... " .Konstanty jsou definovány v hlavičkovém souboru public/ccl/inc/db_defines.h .
Zdrojový kód funkce cocka_4 je následující:
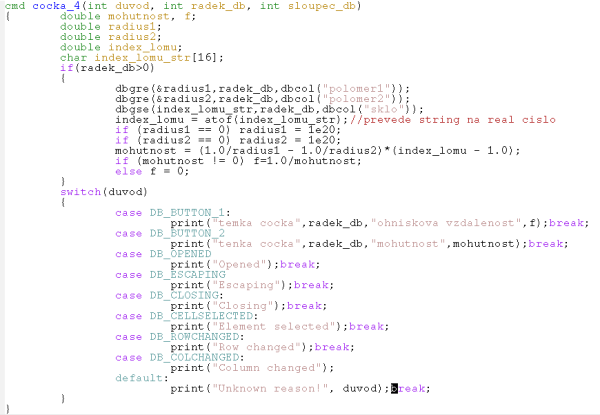
2. 5. Databáze volá funkci, která z ní přebírá data a zapisuje do buněk databáze
Tento příklad užívá databázi jedcocka_5.cdb, která obsahuje oproti předchozím případům jeden sloupec navíc pro hodnoty ohniskové vzdálenosti. Místo toho, aby se ohnisková vzdálenost zobrazovala ve výstupním textovém okně, zapisuje se přímo do databáze. K tomu se využívá příkaz:
dbpre (nezkráceně - db_put_real_element), který umožňuje zapsat reálná čísla do databáze.
Funkcí cocka_5 vypočtená ohnisková vzdálenost je první argument příkazu dbpre a číslo řádku a číslo sloupce databáze, kam se má zapsat, jsou druhým a třetím argumentem. Zpětné volání se generuje automaticky kdykoliv je vybrána nová buňka v tabulkovém procesoru. Výběr řádkových knoflíků nevyvolá zpětné volání. Jestliže změníte poloměr nebo sklo, bude nově změněna i ohnisková vzdálenost. Abyste nově zavedli ohniskové vzdálenosti všech čoček, musíte kliknout na některé buňce v každém řádku. Řídící knoflíky "ohniskova vzdalenost" a "opticka mohutnost" jsou ponechány a zajišťují výstup požadovaných veličin do textového okna. V uvedeném příkladě jsou ohniskové vzdálenosti v databázi uvedeny jen pro první 4 čočky, protože bylo kliknuto jen na buňkách prvních čtyř řádků databáze. To je patrné z výpisu textového okna. U 5. a 6. čočky zůstává ohnisková vzdálenost vyplněna nulou. Změna nastane až po kliknutí na některé buňce těchto řádků.
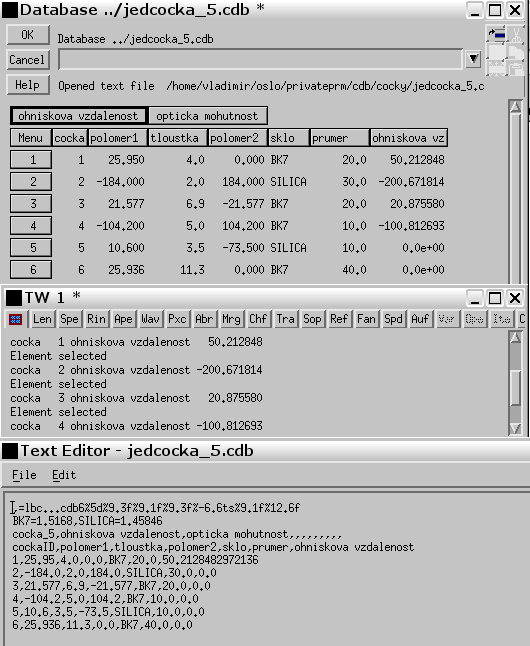
Zdrojový kód funkce cocka_5 je následující:
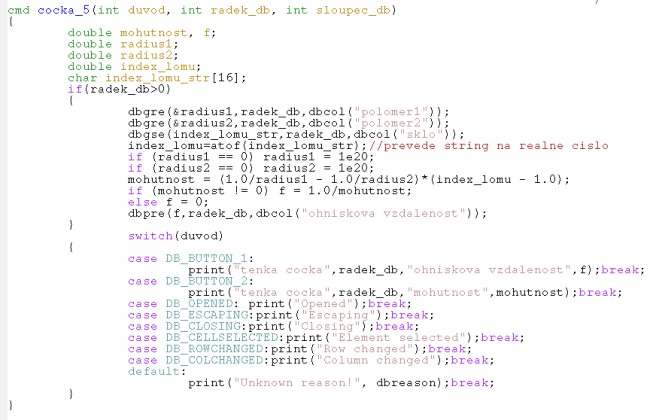
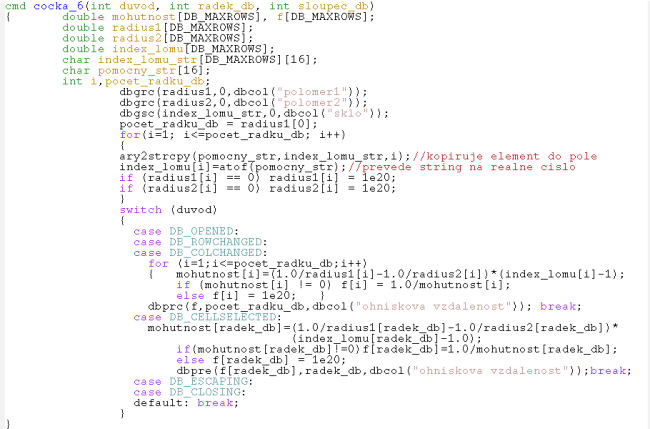
2. 6. Databáze volá funkci, která z ní přebírá data a zapisuje do sloupců databáze
Příklad databázi jedcocka_6.cdb, se od předchozí databáze odlišuje odstraněním knoflíků zpětného voláni. Příkaz cocka_6 nově definuje lokální proměnné na pole, takže všechna významná data v tabulkovém procesoru mohou být obnovena z jednoho zpětného voláni. Tento příklad užívá přístupové funkce ke sloupcum dbrgc (db_get_real_column) a dbgsc (db_get_string_column) a také funkci db_prc (db_put_real_column) k zápisu ohniskových vzdáleností do databáze, když je databáze na počátku otevřena, nebo když jsou řádky nebo sloupce změněny (například při vkládáni nových řádku, nebo při jejich vymazáni.
Proměnná "duvod" je užita k rozhodnutí co se má dělat. Pro důvody DB_OPENED, DB_ROWCHAGED nebo DB_COLCHANGED je celá databáze obnovena, ale když je důvodem DB_CELLSELECTED, pak je obnoven jen řádek, který obsahuje danou buňku. Konstanty v tomto případě jsou definovány v souboru /ccl/inc/a_global.h , který je uveden na začátku programu.
Obnovování databáze je jednoduché a tabulkový procesor se občas obnovuje i když to není potřebné. Např. volání DB_CELLSELECTED způsobí obnovení kdykoliv je nějaká buňka vybrána a nejen, když jsou její data změněna. Tato procedura by se mohla dělat chyřeji, například srovnáním nových a starých dat, ale uvedený příklad je dosti rychlý, takže nevyžaduje nějakou extra preciznost.
Protože proměnné jsou nyní typu pole, tak operátor adresy & se nepoužije. CCL tabulkový procesor je báze 1, což znamená, že první řádek odpovídá elementu 1. Rozměr pole je nastaven v B_MAXROWS (běžně 2000). Nulový element pole je užit v ke zjištění skutečného počtu řádků databáze (t.j. pocet_radku_db=radius1[0]). Ačkoliv sloupcový vektor má dimenzi větší než je počet řádků, vyplní se jen aktuální počet řádků pomoci sloupcové přístupové funkce. Proměnné jsou lokální pole, což znamená, že když je příkaz cocka_6 vyvolán musí být pro ně k dispozici paměť. Poté co se z funkce opustí, uvolní se paměť pro operační systém. Dimenzování lokálních polí ve funkci cocka_6 přes svoji velikost nezaviní nějaké omezení procesu, pokud je k dispozici dynamická paměť. To neplatí pro statická a globální pole, která trvale rezervují paměť po celou dobu běhu procesu.
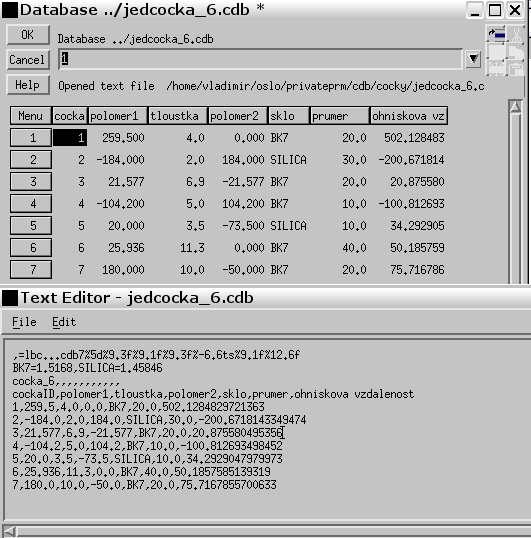
Zdrojový kód funkce cocka_6 je následující: